Hardwaretechnisch (Redundanzen), RAID
Redundante IT-Systeme / IT-Infrastruktur
Redundante IT-Systeme sind entscheidend für die Aufrechterhaltung hoher Verfügbarkeit und Zuverlässigkeit in kritischen Netzwerk- und Anwendungsumgebungen. Redundanz in der IT bedeutet, dass kritische Komponenten doppelt vorhanden sind, um bei einem Ausfall eines Teils weiterhin Betriebssicherheit zu gewährleisten.
Grundlagen der Redundanz
Definition und Ziel
Redundanz in der IT-Infrastruktur bezieht sich auf das Hinzufügen von zusätzlichen Komponenten (Hardware, Software, Netzwerkelemente), die nicht unbedingt für den Grundbetrieb erforderlich sind, aber im Falle eines Ausfalls als Backup dienen. Das Ziel ist es, die Ausfallzeiten zu minimieren und die Datenintegrität und Serviceverfügbarkeit zu maximieren.
Wichtige Konzepte
- Fehlertoleranz: Die Fähigkeit eines Systems, im Falle eines Fehlers normal zu funktionieren.
- Hohe Verfügbarkeit: Gewährleistet, dass ein System eine bestimmte Betriebsdauer ohne Unterbrechungen erreicht.
- Failover: Der Prozess des Umschaltens auf ein redundantes oder Standby-System, wenn das primäre System ausfällt.
Komponenten der Redundanz
Hardware-Redundanz
- Server: Verwendung von mehreren physischen oder virtuellen Servern zur Lastverteilung und zur Bereitstellung eines Backup im Fehlerfall.
- Speicher: Einsatz von RAID-Systemen, mehrfachen Speichereinheiten und automatisierten Backup-Lösungen.
- Netzwerkelemente: Doppelte Netzwerk-Switches, Router und Verbindungswege zur Minimierung von Ausfallrisiken.
- Stromversorgung: Ununterbrechbare Stromversorgungen (USVs) und Generatoren zur Aufrechterhaltung des Betriebs bei Stromausfällen.
Software-Redundanz
- Datenbanken: Spiegelung von Datenbanken oder Einsatz von verteilten Datenbanken zur Gewährleistung der Datenverfügbarkeit.
- Load Balancer: Verteilung der Anfragen auf mehrere Server zur Optimierung der Ressourcennutzung und Minimierung von Ausfallzeiten.
- Clustering: Gruppierung mehrerer Server, die so konfiguriert sind, dass sie als ein einzelnes System arbeiten.
Netzwerk-Redundanz
- Mehrfache Datenpfade: Nutzung verschiedener Netzwerkpfade zur Vermeidung von Engpässen und Ausfällen.
- Redundante Netzwerkverbindungen: Einsatz von mindestens zwei Methoden zur Verbindung mit dem Internet, z.B. über verschiedene ISPs.
Strategien zur Implementierung von Redundanz
Planung und Design
- Risikoanalyse und Bewertung: Bestimmung kritischer Komponenten und potenzieller Risiken.
- Schlüsselindikatoren festlegen: Bestimmung von Recovery Point Objective (RPO) und Recovery Time Objective (RTO).
Implementierung
- Schrittweise Einführung: Implementierung der Redundanz beginnend bei den kritischsten Systemen.
- Regelmäßige Tests: Durchführung von regelmäßigen Tests zur Überprüfung der Wirksamkeit der Redundanzmaßnahmen.
Wartung und Überwachung
- Überwachungstools: Einsatz von Software zur ständigen Überwachung der Leistung und Gesundheit der Systeme.
- Updates und Patches: Regelmäßige Updates zur Gewährleistung der Sicherheit und Funktionalität.
Erweiterte Redundanzkonzepte
In Ergänzung zu den allgemeinen Konzepten der IT-Redundanz gibt es spezifische Redundanzkonzepte, die in verschiedenen Bereichen der Infrastruktur verwendet werden, um die Verfügbarkeit und Zuverlässigkeit zu erhöhen. Besonders verbreitet sind die Konzepte der n+1 und n+2 Redundanz. Diese Konzepte helfen, die Resilienz von Systemen gegen Ausfälle zu verbessern und sicherzustellen, dass kritische Dienste kontinuierlich verfügbar bleiben.
n+1 Redundanz
Die n+1 Redundanz ist eine häufig verwendete Strategie, bei der “n” die Anzahl der für den normalen Betrieb erforderlichen Einheiten darstellt und “+1” eine zusätzliche Einheit für den Fall eines Ausfalls der Haupteinheit. Dieser Ansatz ist besonders effektiv, um gegen einzelne Ausfälle abgesichert zu sein. Hier einige Beispiele:
- Server: In einem Rechenzentrum können zehn Server benötigt werden, um die Last zu bewältigen. Bei einer n+1-Konfiguration würde ein elfter Server hinzugefügt, der einspringt, sollte einer der anderen ausfallen.
- Stromversorgung: Einsatz einer zusätzlichen USV (unterbrechungsfreie Stromversorgung) neben den für den Betrieb erforderlichen USVs.
n+2 Redundanz
Die n+2 Redundanz geht noch einen Schritt weiter als die n+1 Redundanz, indem zwei zusätzliche Einheiten bereitgestellt werden. Dies erhöht die Sicherheit und Verfügbarkeit weiter, indem sie Schutz gegen zwei gleichzeitige Ausfälle bietet. Dies ist besonders in kritischen Umgebungen nützlich, wo der Ausfall von zwei Geräten gleichzeitig zwar unwahrscheinlich, aber möglich ist. Beispiele hierfür sind:
- Klimaanlagen: In einem Serverraum sind drei Klimaanlagen für eine angemessene Kühlung erforderlich. Bei einer n+2 Konfiguration wären insgesamt fünf Klimaanlagen installiert.
- Netzwerkrouter: Zwei zusätzliche Router werden bereitgestellt, um sicherzustellen, dass der Netzwerkverkehr auch im Falle des Ausfalls zweier primärer Router weiterhin fließen kann.
2N Redundanz
Ein weiteres Konzept ist die 2N Redundanz, die eine vollständige Verdopplung der kritischen Infrastruktur vorsieht. Hierbei wird jedes System oder jede Komponente komplett dupliziert, sodass bei einem Ausfall eines Systems das identische Backup-System sofort einspringen kann. Diese Art der Redundanz ist extrem sicher, aber auch kostspielig und wird oft in hochsensiblen Bereichen eingesetzt, wie z.B.:
- Datenzentren: Vollständige Duplizierung aller Hardwarekomponenten und Netzwerkinfrastrukturen.
- Stromzufuhr: Einsatz von zwei völlig unabhängigen Stromversorgungsquellen.
Geografische Redundanz
Diese Art der Redundanz bezieht sich auf die physische Verteilung von Daten und Diensten auf verschiedene geografische Standorte. Im Falle eines regionalen Ausfalls, wie z.B. durch Naturkatastrophen oder größere Stromausfälle, bleibt die Dienstleistung durch die anderen Standorte unbeeinträchtigt. Dies ist besonders wichtig für globale Dienste, die hohe Verfügbarkeit erfordern.
Vorteile der IT-Redundanz
- Reduzierte Ausfallzeiten: Minimierung der Zeit, die für die Wiederherstellung nach einem Ausfall benötigt wird.
- Verbesserte Kundenzufriedenheit: Durch die Gewährleistung eines zuverlässigen Betriebs.
- Erhöhte Datenintegrität: Schutz kritischer Daten vor Verlust oder Beschädigung.
- Skalierbarkeit: Möglichkeit zur Erweiterung der Infrastruktur, ohne die Betriebssicherheit zu beeinträchtigen.
Herausforderungen
- Kosten: Die Implementierung redundanter Systeme kann teuer sein.
- Komplexität: Erhöht die Komplexität der Infrastruktur und des Managements.
- Ressourcenbedarf: Erfordert zusätzliche Ressourcen und Fachwissen zur Verwaltung.
RAID-Systeme
Überblick
RAID steht für “Redundant Array of Independent Disks” und bezeichnet eine Technologie, die mehrere physische Festplatten verwendet, um Daten redundant zu speichern oder die Leistung zu verbessern.
RAID Funktionsweisen
Spiegelung (Mirroring)
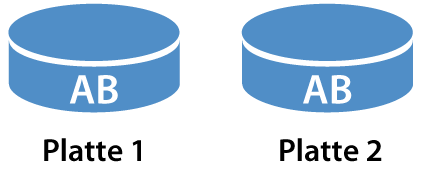
Bei der Spiegelung wird ein Datensatz “AB” komplett auf zwei verschiedenen Festplatten abgespeichert. Beim Ausfall einer Platte gehen keine Informationen verloren, da der ganze Datensatz auch auf der zweiten Platte vorhanden ist.
Streifen (Striping)
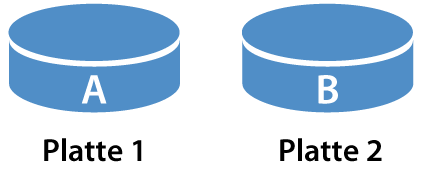
Beim Streifen wird ein Datensatz “AB” aufgeteilt und auf mehrere aufeinanderfolgende Festplatten gespeichert. Beim Ausfall einer Platte sind alle Informationen verloren, da sämtliche Platten benötigt werden, um den Datensatz vollständig lesen zu können.
Mit Streifen wird die Lese- und Schreibgeschwindigkeit erhöht, da von mehreren Festplatten gleichzeitig gelesen werden kann.
Parität (Parity)
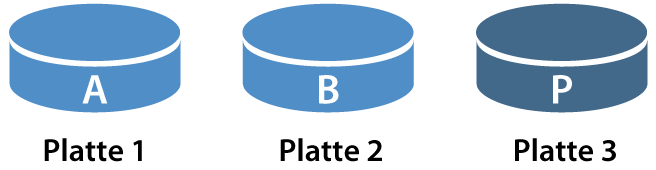
Parität ergänzt jeden Streifen mit der Möglichkeit, in einen Datensatz verlorene Informationen wiederherzustellen. Ein Datensatz “AB” wird mit Streifen auf mehrere Platten verteilt. Auf einer zusätzlichen Platte wird für jeden Streifen ein Paritätswert “P” errechnet. Fällt eine Platte aus, kann mit Hilfe der Parität die fehlende Information errechnet werden.
Ein vereinfachtes Beispiel: Sie speichern auf zwei Festplatten je eine Zahl: 4 und 7. Auf der dritten Paritätsplatte speichern Sie die Summe der beiden Zahlen: 11. Fällt eine der beiden Platten aus, können Sie mit Hilfe der Summe die fehlende Zahl berechnen.
Tabellarische Übersicht:
| RAID-Level | RAID 0 | RAID 1 | RAID 5 | RAID 6 | RAID 10 (1+0) | RAID 50 | RAID 60 |
|---|---|---|---|---|---|---|---|
| Mindestanzahl an Festplatten | 2 | 2 | 3 | 4 | 4 | 6 (2 Gruppen von 3 Disks) | 8 (2 Gruppen von 4 Disks) |
| Verwendete Verfahren | Striping | Spiegelung (Mirroring) | Striping und Parität | Striping und doppelte Parität | Striping gespiegelter Daten | Kombination von RAID 5 und Striping | Kombination von RAID 6 und Striping |
| Ausfallsicherheit | niedrig | sehr hoch; Ausfall eines Laufwerks möglich | mittel; Ausfall eines Laufwerks möglich | hoch; Ausfall von zwei Laufwerken möglich | sehr hoch; Ausfall eines Laufwerks pro Sub-Array möglich | hoch; Ausfall eines Laufwerks pro RAID-5-Gruppe möglich | sehr hoch; Ausfall von zwei Laufwerken pro RAID-6-Gruppe möglich |
| Speicherkapazität für Nutzdaten | 100 Prozent | 50 Prozent | 67 Prozent (steigt mit jeder weiteren Platte) | 50 Prozent (steigt mit jeder weiteren Platte) | 50 Prozent | Über 67 Prozent, abhängig von der Anzahl der Disks | Über 50 Prozent, abhängig von der Anzahl der Disks |
| Geschwindigkeit beim Schreiben | sehr hoch | niedrig | mittel | niedrig | mittel | hoch | mittel |
| Geschwindigkeit beim Lesen | sehr hoch | mittel | hoch | hoch | sehr hoch | sehr hoch | hoch |
| Kostenfaktor | niedrig | sehr hoch | mittel | hoch | sehr hoch | sehr hoch | sehr hoch |
Erklärung Prüfungsrelevanter RAID-Systeme
RAID 0 (Striping)
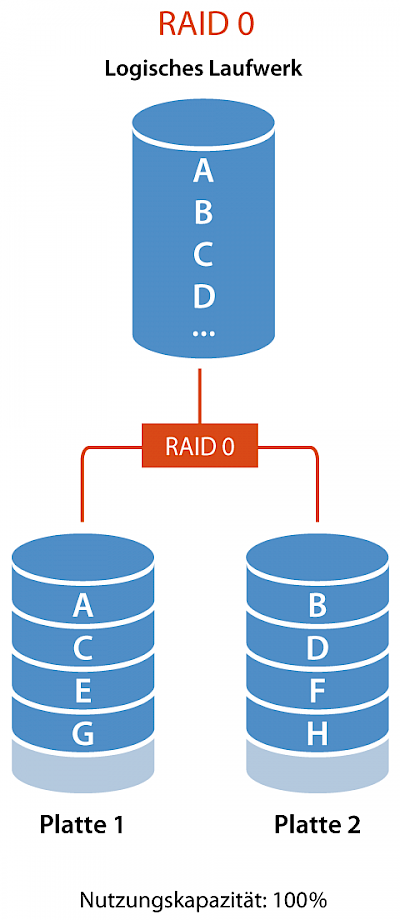
- Beschreibung: Teilt Daten gleichmäßig ohne Parität über zwei oder mehr Festplatten. Dies erhöht die Leistung, bietet jedoch keine Redundanz.
- Kapazität: Kapazität = N * kleinste Festplattengröße
- Redundanz: Keine
- Beispiel: 2 Disks zu je 1TB bieten eine Gesamtkapazität von 2TB.
RAID 1 (Mirroring)
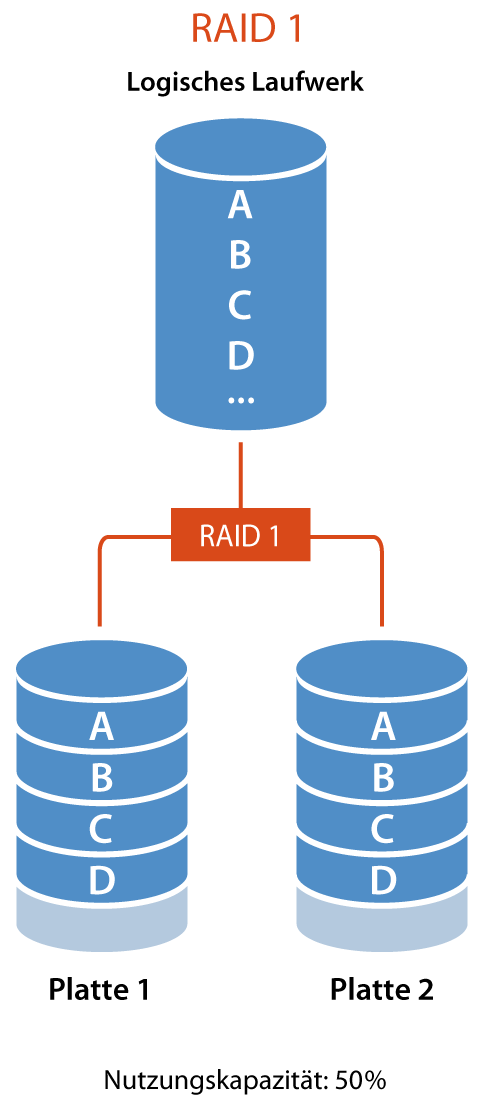
- Beschreibung: Spiegelt Daten auf zwei oder mehr Festplatten. Dies bietet eine hohe Redundanz, aber die nutzbare Kapazität entspricht nur der eines Laufwerks.
- Kapazität: Kapazität = kleinste Festplattengröße
- Redundanz: Vollständig
- Beispiel: 2 Disks zu je 1TB bieten eine Gesamtkapazität von 1TB.
RAID 5 (Striping mit Parität)
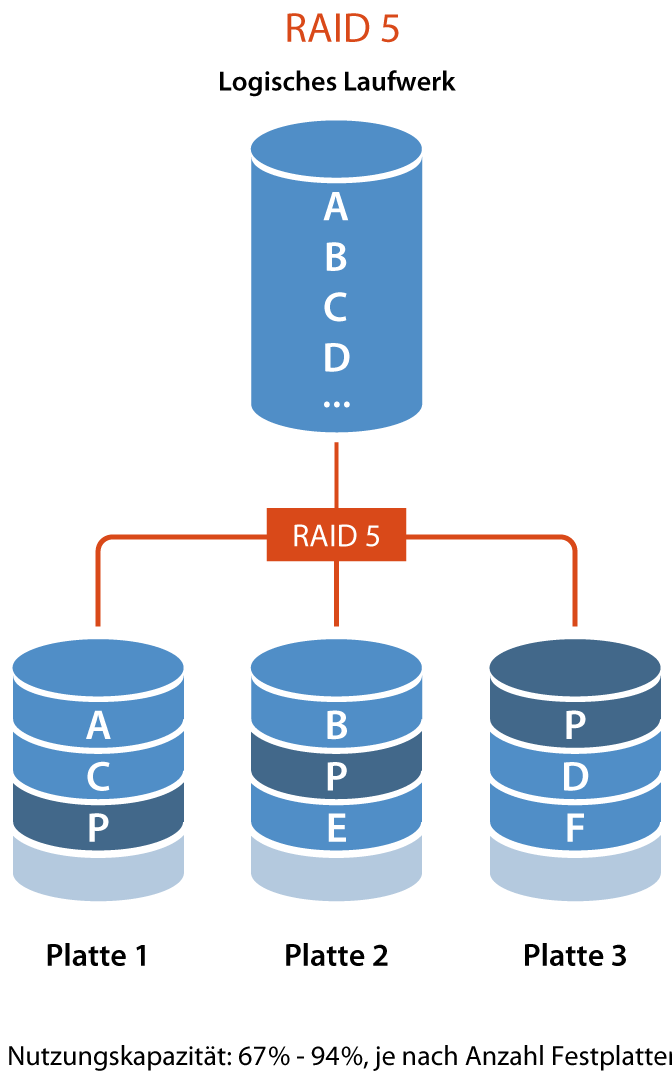
- Beschreibung: Verteilt Paritätsinformationen auf alle Festplatten der Gruppe, was Fehlerkorrektur ermöglicht. Mindestens drei Disks sind erforderlich.
- Kapazität: Kapazität = (N - 1) * kleinste Festplattengröße
- Redundanz: Eine Festplatte kann ausfallen, ohne dass Daten verloren gehen.
- Beispiel: 3 Disks zu je 1TB bieten eine Gesamtkapazität von 2TB.
RAID 6 (Striping mit doppelter Parität)
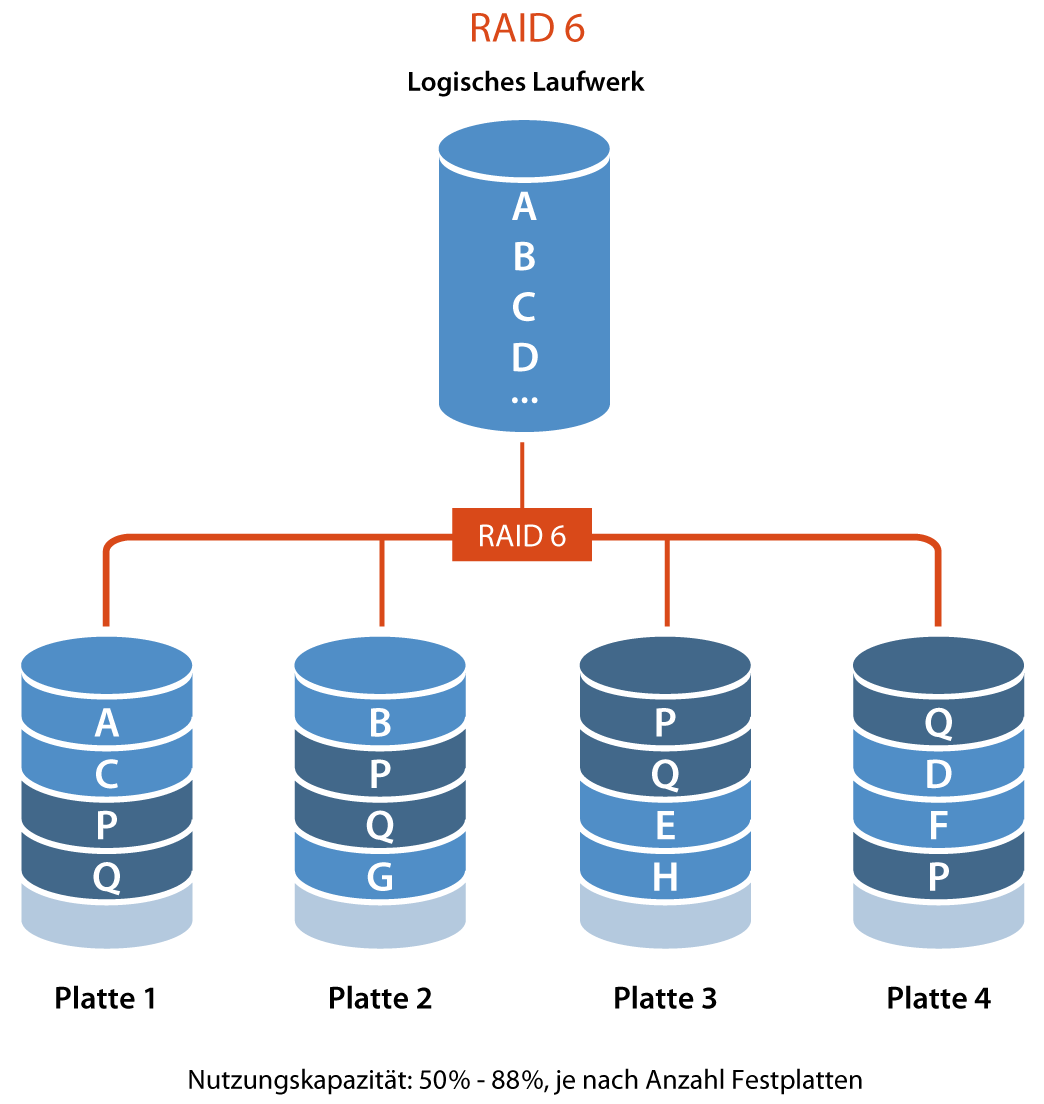
- Beschreibung: Ähnlich wie RAID 5, aber es werden zwei unabhängige Paritätsblöcke verwendet, sodass zwei Disks ausfallen können.
- Kapazität: Kapazität = (N - 2) * kleinste Festplattengröße
- Redundanz: Zwei Festplatten können ausfallen.
- Beispiel: 4 Disks zu je 1TB bieten eine Gesamtkapazität von 2TB.
RAID 10 (1+0)
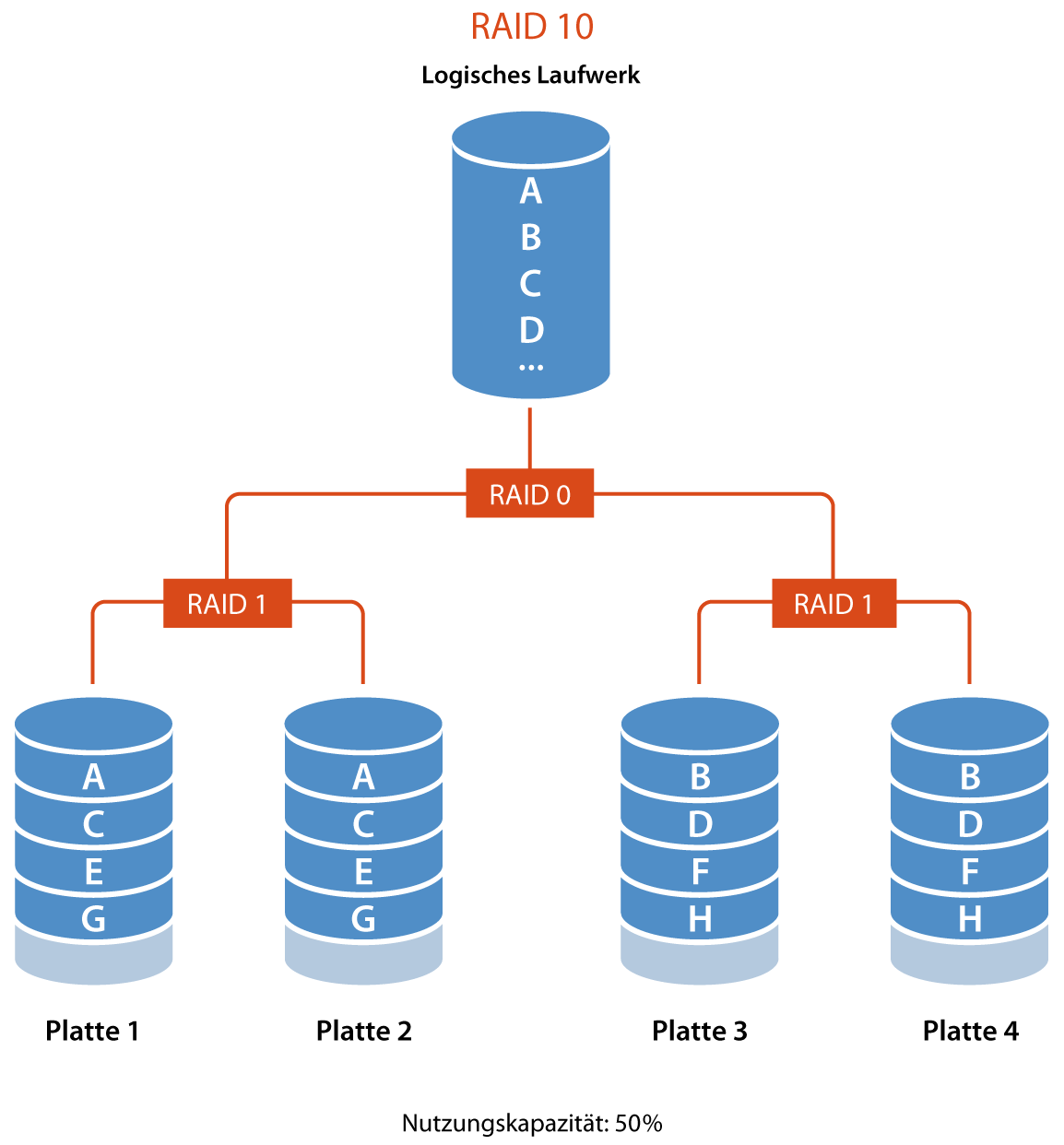
- Beschreibung: Kombination aus Mirroring und Striping. Es bietet die Vorteile von RAID 0 und RAID 1.
- Kapazität: Kapazität = (N / 2) * kleinste Festplattengröße
- Redundanz: Eine Disk pro Spiegel kann ausfallen.
- Beispiel: 4 Disks zu je 1TB bieten eine Gesamtkapazität von 2TB.
Wichtige Überlegungen
- Ausfallsicherheit: RAID ist keine Backup-Lösung. Es bietet Redundanz zum Schutz gegen Hardware-Ausfälle, nicht gegen Datenkorruption oder -verlust aus anderen Gründen.
- Performance: RAID-Level, die Striping verwenden (z.B. RAID 0, 5, 10), können die Lese- und Schreibgeschwindigkeit verbessern.
- Kosten und Nutzen: Höhere RAID-Level bieten bessere Redundanz und Leistung, sind aber teurer in der Implementierung, da mehr Festplatten benötigt werden.
Hot Spare
Ein Hot Spare ist eine Reservefestplatte, die in einem RAID-Array oder Server eingebaut, aber nicht aktiv genutzt wird. Sie dient dazu, im Falle eines Ausfalls einer aktiven Festplatte automatisch und ohne manuellen Eingriff deren Funktion zu übernehmen. Der Hauptvorteil eines Hot Spares liegt in der schnellen Wiederherstellung der vollen RAID-Funktionalität und Redundanz, da die Rekonstruktion des RAID-Arrays sofort beginnen kann, sobald eine Festplatte ausfällt. Dies reduziert das Risiko eines Datenverlustes während der Wiederherstellung.
Hot Swap
Hot Swap bezeichnet die Fähigkeit, eine Komponente – typischerweise eine Festplatte – zu entfernen und zu ersetzen, während das System in Betrieb ist, ohne dass dieses heruntergefahren werden muss. Diese Fähigkeit ist besonders wertvoll in Umgebungen, die eine hohe Verfügbarkeit erfordern, wie z.B. Datenzentren und Serverräume. Hot Swapping ermöglicht die Wartung oder den Austausch von Hardware, ohne die Systemleistung oder Verfügbarkeit zu beeinträchtigen.
Quellen
19.04.2024 Tabelle Content + Bilder